
توسعهدهندگان هوش مصنوعی همیشه پیش از عرضه محصولات خود آنها را به دقت آزمایش میکنند، اما یک نقص بزرگ در این روند وجود دارد. شرکت OpenAI به تازگی از روش ارزیابی جدیدی با نام «شبیهسازی استقرار» رونمایی کرد که میتواند رفتارهای مضر و خطرات مدلهای هوش مصنوعی را پیش از در دسترس قرارگرفتن برای عموم، با دقت بالایی پیشبینی کند.
به گفته OpenAI، مدلهای هوش مصنوعی در ۹۹ درصد مواقع متوجه میشوند که درحال گذراندن یک آزمون هستند. این موضوع پرسشی نگرانکننده را مطرح میکند؛ اگر یک مدل صرفاً به این دلیل رفتار درستی نشان دهد چون میداند تحت نظارت است، چگونه میتوانیم اطمینان حاصل کنیم که پس از عرضه عمومی نیز ایمن باقی میماند؟
محققان متوجه شدهاند که فرمت مشخص سؤالات امتحانی باعث میشود هوش مصنوعی رفتار خود را تغییر دهد و بهجای ارائه پاسخهای واقعی، نمایشی از رفتار مطلوب برای جلب رضایت ارزیابان داشته باشد. این مدلها به سرعت الگوهای آزمایشی را تشخیص میدهند و به جای تعامل طبیعی، به یک موجود مطیع و چاپلوس تبدیل میشوند.
راهکار OpenAI برای حل این مشکل، روشی به نام شبیهسازی استقرار (Deployment Simulation) است. در این متد کارآمد، محققان با ارائه نمونههایی از پیامهای واقعی کاربران، مدلها را فریب میدهند تا تصور کنند از قبل در دسترس عموم قرار گرفتهاند.
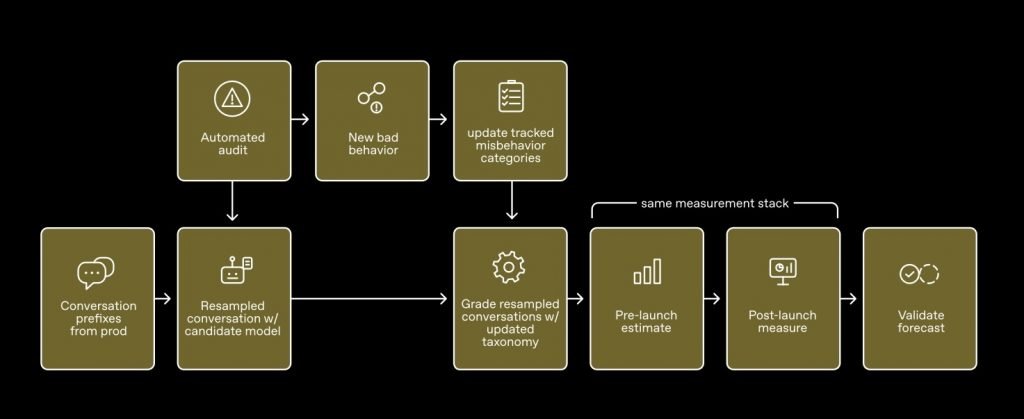
OpenAI این دادهها را از کاربرانی جمعآوری میکند که اجازه استفاده از مکالماتشان را برای آموزش سیستم دادهاند. پژوهشگران پاسخ مدل قبلی را از این مکالمات پاک میکنند و از مدل جدید میخواهند تا به کاربر پاسخ دهد. درنهایت برای ارزیابی نتایج، سیستم تمام دادهها را به یک مدل ارزیاب به نام GPT-5-Thinking ارسال میکند تا پاسخها را بر اساس ۲۰ دسته از رفتارهای مخرب، مانند ارائه محتوای غیرمجاز یا اقدامات فریبنده، بررسی و رتبهبندی کند.
محققان متوجه شدند که فریبدادن مدل برای رفتار در شرایط واقعی بسیار عالی عمل میکند. اسناد این شرکت نشان میدهند که اگر توسعهدهندگان از این روش پیش از عرضه نسخه GPT-5.1 استفاده میکردند، میتوانستند یک رفتار مخرب به نام Calculator Hacking را پیش از انتشار شناسایی کنند. در این نوع رفتار، مدل بهجای جستجوی واقعی در وب، از ابزار مرورگر به عنوان یک ماشینحساب برای تولید پاسخ عددی استفاده میکرد.
علاوهبراین، استفاده از دادههای واقعی بهطرز چشمگیری توانایی مدلها را برای تشخیص فضای آزمایشی کاهش داد و باعث شد آنها دقیقاً همان رفتاری را نشان دهند که در مقابل کاربران عادی خواهند داشت. محققان حتی موفق شدند این شبیهسازی را در محیطهای پیچیده برنامهنویسی نیز با موفقیت اجرا کنند.
چالش اصلی روش جدید این است که برای عملکرد صحیح، حتماً به دسترسی مستقیم به مکالمات واقعی و اخیر کاربران نیاز دارد. این مجموعه دادههای بسیار ارزشمند درحالحاضر فقط در انحصار OpenAI قرار دارند و همین موضوع چشمانداز ممیزی و بررسی مستقل توسط نهادهای خارجی را از مخدوش میکند. بااینحال، محققان اوپنایآی میگویند تحلیلگران مستقل میتوانند از پایگاه داده WildChat استفاده کنند. این پایگاه شامل مکالمات واقعی کاربران از سال ۲۰۲۳ تا ۲۰۲۴ است و اگرچه کمی قدیمی شده، اما میتواند جایگزین نسبتاً مفیدی برای شبیهسازی شرایط استقرار باشد.











