
OpenAI بهتازگی دو مدل زبانی متنباز با نام gpt-oss را منتشر کرد که کاربران میتوانند آنها را روی سیستم خود اجرا کنند. در ادامه آموزش نصب هوش مصنوعی متنباز OpenAI روی سه سیستمعامل ویندوز، لینوکس و macOS را بهصورت تصویری توضیح خواهیم داد.
نسخه سبکتر این مدلها یعنی gpt-oss-20b با 21 میلیارد پارامتر، تنها به حدود 16 گیگابایت حافظه نیاز دارد. در مقابل، مدل سنگینتر با نام gpt-oss-120p شامل 117 میلیارد پارامتر میشود و اجرای آن به 80 گیگابایت حافظه نیاز دارد. برای مقایسه، یک مدل پیشرفته مانند DeepSeek R1 حدود 671 میلیارد پارامتر دارد و برای اجرا به چیزی در حدود 875 گیگابایت حافظه نیاز دارد.
بنابراین اگر سیستم شما یک سرور قدرتمند مخصوص هوش مصنوعی نباشد، بهاحتمال زیاد نمیتوانید مدل gpt-oss-120b را اجرا کنید. اما بسیاری از کاربران خانگی امکان استفاده از مدل gpt-oss-20b را دارند. برای این کار، سیستم شما باید یکی از این دو شرط زیر را داشته باشد:
همچنین عملکرد این مدل بهشدت وابسته به پهنای باند حافظه است. بنابراین کارتهای گرافیک دارای حافظه GDDR7 یا GDDR6X با پهنای باند 1000 گیگابایتبرثانیه یا بیشتر، بسیار بهتر از سیستمهای معمولی با رم DDR4 یا DDR5 (با پهنای باند 20 تا 100 گیگابایتبرثانیه) عمل میکنند.
در ادامه، مراحل اجرای این مدل را بهصورت رایگان روی سیستمعاملهای ویندوز، لینوکس و macOS توضیح میدهیم. برای این کار از Ollama استفاده خواهیم کرد؛ اپلیکیشن رایگانی که نصب و اجرای این مدل زبانی را بسیار ساده میکند.
اجرای این مدل زبانی جدید در ویندوز بسیار ساده است. برای شروع، ابتدا باید برنامه Ollama را برای ویندوز دانلود و نصب کنید.
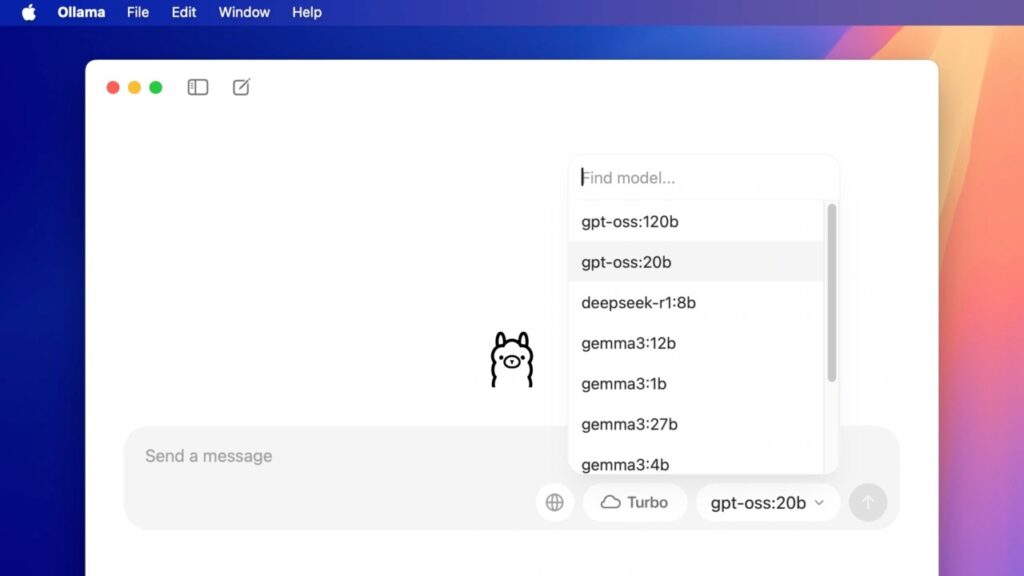
پس از اجرای Ollama، در پنجره اصلی یک فیلد با عنوان Send a message خواهید دید. در پایین سمت راست نیز یک منوی کشویی قرار دارد که مدلهای قابل استفاده را نمایش میدهد. بهصورت پیشفرض، مدل gpt-oss:20b انتخاب شده است. میتوانید مدل دیگری را انتخاب کنید، اما فعلاً با همین مدل کار را ادامه میدهیم.
در فیلد پیام، هر دستوری که دوست دارید را میتوانید وارد کنید. پس از وارد کردن پیام، برنامه شروع به دانلود فایل مدل کرده که حجمی برابر با 12.4 گیگابایت دارد. سرعت دانلود ممکن است پایین باشد، پس کمی صبور باشید.
پس از اتمام دانلود، میتوانید هر دستوری که مایل هستید را وارد کرده و با کلیک روی دکمه فلش، پاسخ آن را دریافت کنید.
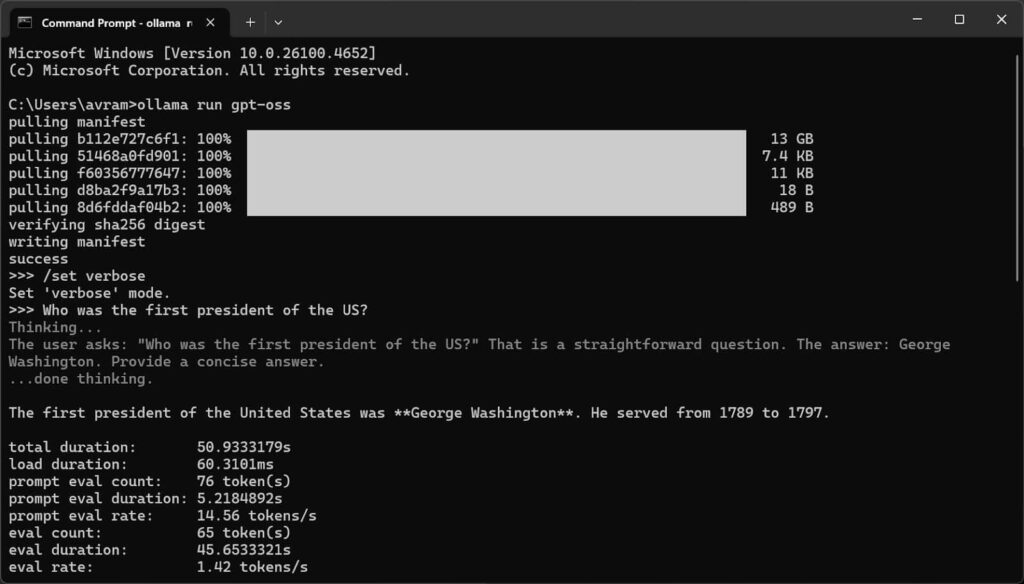
همچنین اگر ترجیح میدهید بدون رابط گرافیکی (GUI) و از طریق خط فرمان کار کنید، Ollama این امکان را نیز فراهم کرده است. در واقع، اجرای برنامه از طریق Command Prompt مزایایی هم دارد؛ مثل فعالسازی حالت verbose که آمار عملکرد مدل مانند مدت زمان پاسخدهی را نمایش میدهد.
برای اجرای Ollama از طریق CMD، ابتدا باید این دستور را وارد کنید:
ollama run gpt-oss
اگر این اولین بار است که این مدل را اجرا میکنید، Ollama بهطور خودکار مدل را از اینترنت دانلود خواهد کرد. پس از دانلود و نمایش اعلان آماده به کار، این دستور را وارد کنید:
/set verbose
در نهایت، درخواست خود را تایپ کرده و Enter بزنید تا مدل پاسخ دهد.
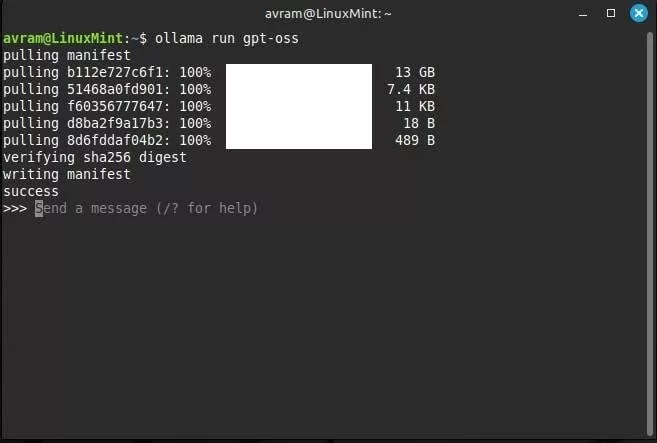
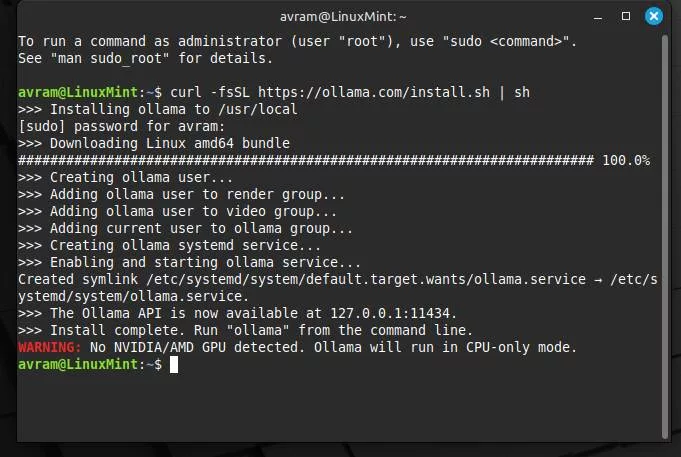
برای اینکه مدل OpenAI را روی لینوکس اجرا کنید، ابتدا باید یک پنجره ترمینال باز کنید. سپس دستور زیر را در ترمینال وارد کنید:
curl -fsSL https://ollama.com/install.sh | sh
با این کار، برنامه Ollama بهصورت خودکار دانلود و نصب خواهد شد. بسته به سرعت اینترنت شما، ممکن است فرایند دانلود چند دقیقه طول بکشد.
پس از اتمام نصب، برای اجرای مدل gpt-oss:20b این دستور را وارد کنید:
ollama run gpt-oss
در اولین اجرا، حدود ۱۳ گیگابایت داده باید دانلود شود تا مدل آماده به کار شود. پس از آن، میتوانید درخواست خود را وارد کرده و پاسخ مدل را دریافت کنید.
با دستور زیر هم میتوانید حالت verbose را فعال کنید تا آمارهایی مانند مدت زمان پاسخدهی مدل را مشاهده کنید:
/set verbose
سپس میتوانید پیام یا دستور خود را تایپ کرده و اجرا کنید.
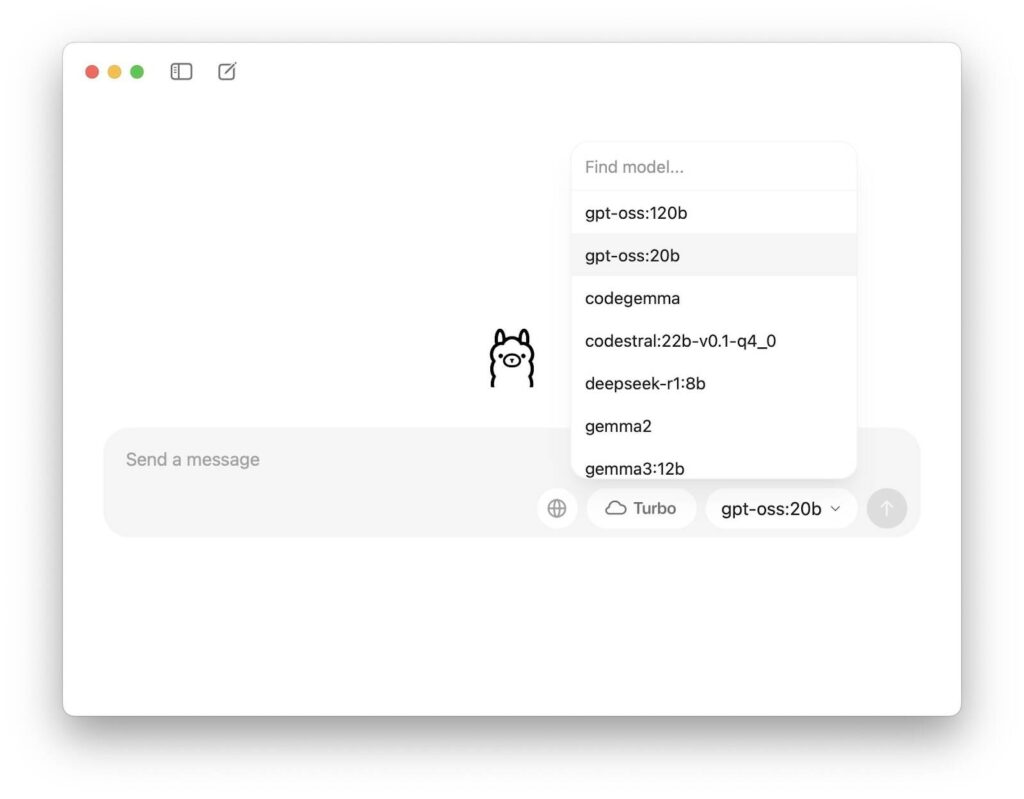
اگر از مکبوک یا مک دسکتاپی با پردازنده M1 یا بالاتر استفاده میکنید، اجرای مدل gpt-oss-20b بهسادگی نسخه ویندوز خواهد بود. کافی است نسخه مخصوص macOS از برنامه Ollama را دانلود و نصب کنید.
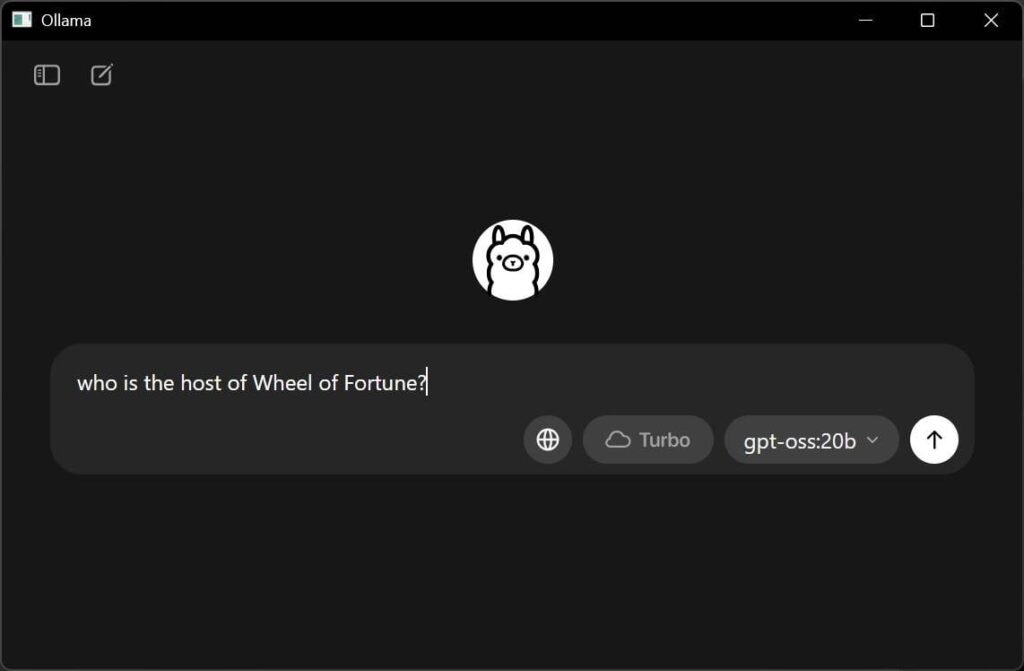
پس از نصب، برنامه را اجرا کرده و مطمئن شوید که مدل انتخابشده gpt-oss:20b باشد.
سپس در فیلد پیام، درخواست خود را وارد کرده و روی دکمه فلش رو به بالا کلیک کنید تا پاسخ مدل را دریافت کنید. به همین سادگی در مک خود توانستهاید از هوش مصنوعی OpenAI استفاده کنید.
رسانه The Register برای آزمایش عملکرد این مدل روی لپتاپها، چند دستگاه مختلف را انتخاب کرده است:
به هر سه دستگاه نیز دستور نوشتن یک نامه عاشقانه و سوال «اولین رئیسجمهور آمریکا چه کسی بود؟» ارائه شده است.
این رسانه میگوید که روی لپتاپ تینکپد X1، عملکرد بسیار ضعیف بوده، چون Ollama فعلاً نمیتواند از گرافیک مجتمع یا واحد پردازش عصبی (NPU) این دستگاه استفاده کند و تمام بار پردازش روی CPU افتاد. بههمیندلیل تولید نامه عاشقانه ۱۰ دقیقه و ۱۳ ثانیه طول کشیده است!
پاسخ به سوال ساده «اولین رئیسجمهور آمریکا چه کسی بود؟» نیز ۵۱ ثانیه به کاربر ارائه شده است.
مکبوک پرو و تینکپد رم یکسانی دارند، اما این گزارش میگوید که دستگاه اپل با اختلاف بسیار بهتر عمل کرده است. مک بوک نامه را در 26 ثانیه نوشته و تنها در ۳ ثانیه به سوال پاسخ داده است.
اما طبق انتظار، سیستم دسکتاپ با کارت گرافیک قدرتمند RTX 6000 بهترین عملکرد را داشته است. این سیستم نامه را در ۶ ثانیه و پاسخ سوال را در کمتر از نیم ثانیه تولید کرده است.











