
زبان یکی از مهمترین ابزارهای ارتباطی انسانهاست و همواره تلاش شده تا ماشینها نیز بتوانند زبان ما را درک کنند. پردازش زبان طبیعی (NLP) شاخهای از هوش مصنوعی است که به کامپیوترها امکان میدهد متن و گفتار انسانی را تجزیه، تحلیل و حتی تولید کنند. از موتورهای جستجو گرفته تا دستیارهای هوشمند مانند Siri و ChatGPT، همگی بر پایه تکنیکهای پردازش زبان طبیعی کار میکنند. در این مقاله بهطور کامل بررسی میکنیم که پردازش زبان طبیعی چیست، چه الگوریتمها و مفاهیمی در آن به کار میرود و چه کاربردهایی در صنایع مختلف دارد.
فهرست مطالب

پردازش زبان طبیعی یا Natural Language Processing (NLP) ترکیبی از علوم کامپیوتر، هوش مصنوعی و زبانشناسی محاسباتی است که هدف آن آموزش به کامپیوترها برای درک و استفاده از زبان انسانی است. در واقع، NLP همان پلی است که ارتباط میان زبان انسان و زبان ماشین را برقرار میکند.
وقتی انسانها با یکدیگر صحبت یا مکاتبه میکنند، بهطور ناخودآگاه از قواعد دستوری، معناشناسی و حتی لحن استفاده میکنند. اما ماشینها زبان ما را به شکل دادههای خام میبینند. پردازش زبان طبیعی تلاش میکند این فاصله را پر کند تا رایانه بتواند متون و گفتار انسانی را نهتنها بخواند، بلکه مفهوم آن را نیز بفهمد و پاسخ مناسب ارائه دهد.
بهطور خلاصه، NLP مجموعهای از تکنیکها و الگوریتمهاست که به سیستمها امکان میدهد کارهایی مانند ترجمه خودکار متن، شناسایی احساسات، تولید محتوای متنی، پاسخگویی به سؤالات و حتی تشخیص گفتار را انجام دهند. امروزه بسیاری از سرویسهای هوشمند مانند موتورهای جستجو، چتباتها، سیستمهای پشتیبانی مشتری، و ابزارهای تحلیل شبکههای اجتماعی، از پردازش زبان طبیعی بهره میبرند.
پیشنهاد مطالعه: هوش مصنوعی چیست؟
پردازش زبان طبیعی بر پایه دو رکن اصلی بنا شده است که در کنار هم به ماشینها کمک میکنند زبان انسان را درک کرده و تولید کنند. این دو رکن عبارتاند از درک زبان طبیعی (NLU) و تولید زبان طبیعی (NLG).
درک زبان طبیعی یا (NLU) Natural Language Understanding مسئول بخش «فهمیدن» است. این بخش به سیستم کمک میکند متن یا گفتار ورودی را تجزیه و تحلیل کرده و معنا، ساختار دستوری، موجودیتهای مهم و روابط بین کلمات را تشخیص دهد. برای مثال، وقتی شما در یک موتور جستجو عبارت «رستورانهای نزدیک من» را وارد میکنید، NLU تشخیص میدهد که هدف شما پیدا کردن مکانهای نزدیک محل زندگیتان است، نه صرفاً کلمه «رستوران».
تولید زبان طبیعی یا (NLG) Natural Language Generation بخش «پاسخ دادن» یا تولید محتوا توسط ماشین است. در این مرحله سیستم براساس دادهها یا تحلیلهای قبلی، یک متن یا گفتار طبیعی تولید میکند. برای نمونه، وقتی یک چتبات پس از پرسش شما درباره وضعیت پرواز میگوید: «پرواز شما در ساعت ۱۸:۳۰ از فرودگاه امام خمینی انجام خواهد شد»، این متن توسط بخش تولید زبان طبیعی ساخته شده است.
به بیان ساده، میتوان گفت NLU مانند گوش و مغز سیستم است که زبان را میفهمد، و NLG مانند دهان سیستم است که با زبان انسان پاسخ میدهد. ترکیب این دو رکن باعث شده است که تعامل انسان و ماشین به سطحی فراتر از دستورهای ساده برسد و شبیه یک گفتوگوی طبیعی شود.
پردازش زبان طبیعی قدمتی بیش از نیم قرن دارد و مسیر رشد آن با پیشرفتهای علمی در حوزههای زبانشناسی و هوش مصنوعی گره خورده است. این حوزه در دهه ۱۹۵۰ میلادی و همزمان با ظهور اولین رایانهها مطرح شد. یکی از نخستین تلاشها در این زمینه، پروژه ترجمه ماشینی بین زبان روسی و انگلیسی بود که نشان داد اگرچه ایده جذاب است، اما محدودیتهای زبانی بسیار پیچیدهتر از آن چیزی است که در نگاه اول تصور میشد.
در دهههای ۶۰ و ۷۰، بیشتر تلاشها بر پایه الگوریتمهای Rule-based (قانونمحور) انجام میشد. در این روش، قواعد دستوری و زبانی به صورت دستی وارد سیستم میشدند، اما مشکل اصلی آن مقیاسپذیری پایین و ناتوانی در پوشش همه استثناها بود.
با ورود به دهه ۹۰ میلادی و گسترش دادههای متنی، رویکردهای آماری (Statistical NLP) جایگزین شدند. در این دوره، الگوریتمها از حجم زیادی داده برای یادگیری الگوهای زبانی استفاده کردند و دقت سیستمها به شکل قابل توجهی افزایش یافت.
از سال ۲۰۱۰ به بعد، با پیشرفت یادگیری عمیق (Deep Learning) و معرفی شبکههای عصبی عمیق، NLP وارد مرحلهای تازه شد. مدلهایی مانند Word2Vec توانستند کلمات را به بردارهای معنایی تبدیل کنند و سپس مدلهای پیچیدهتر مثل BERT و GPT به وجود آمدند که توانایی بیسابقهای در درک متن و تولید زبان طبیعی داشتند.
امروزه، پردازش زبان طبیعی یکی از ستونهای اصلی فناوریهای هوش مصنوعی به شمار میرود و در حوزههایی مانند چتباتها، موتورهای جستجو، ترجمه ماشینی، تحلیل احساسات و تولید محتوا کاربرد گسترده دارد.
پردازش زبان طبیعی یک حوزه میانرشتهای است که از ترکیب چند دانش اصلی شکل گرفته است. برای درک بهتر، باید با برخی از زیرشاخهها و مفاهیم پایهای آن آشنا شویم.
زبانشناسی محاسباتی علمی است که به مطالعه ساختار زبان و مدلسازی آن توسط رایانهها میپردازد. در این بخش قواعد دستوری، معنایی و نحوی زبان استخراج میشوند تا الگوریتمهای پردازش زبان طبیعی بتوانند روی آنها عمل کنند. در واقع، این حوزه پلی میان زبانشناسی و علوم کامپیوتر است.
با ورود یادگیری ماشین (Machine Learning)، پردازش زبان طبیعی توانست از روشهای صرفاً قاعدهمحور فاصله بگیرد. الگوریتمهای یادگیری ماشین با تحلیل حجم عظیمی از دادههای متنی، الگوهای زبانی را کشف کرده و مدلهایی ایجاد میکنند که میتوانند وظایفی مثل طبقهبندی متن یا تحلیل احساسات را انجام دهند.
یادگیری عمیق (Deep Learning) در سالهای اخیر، یادگیری عمیق تحول بزرگی در NLP ایجاد کرده است. شبکههای عصبی عمیق مانند RNN، LSTM و ترنسفورمرها توانستهاند درک معنایی و بافتاری از زبان را ممکن کنند. همین پیشرفتها زمینهساز توسعه مدلهای پیشرفتهای مانند BERT و GPT شدند که امروز در بسیاری از سیستمهای هوشمند به کار میروند.

پردازش زبان طبیعی یک فرایند چندمرحلهای است که دادههای خام زبانی (متن یا گفتار) را به اطلاعات قابل فهم برای ماشین تبدیل میکند. هر مرحله وظیفه خاصی دارد و خروجی آن، ورودی مرحله بعدی خواهد بود.
در این مرحله دادههای متنی برای تحلیل آماده میشوند. پیشپردازش شامل کارهایی مانند:
این کار باعث سادهتر شدن متن و کاهش پیچیدگی محاسبات میشود.
پس از آمادهسازی دادهها، مدلهای مختلف روی آنها آموزش داده میشوند. این مدلها میتوانند مبتنی بر قواعد (Rule-based)، روشهای آماری، یا الگوریتمهای یادگیری ماشین و یادگیری عمیق باشند. انتخاب الگوریتم به نوع وظیفه و حجم داده بستگی دارد.
در آخرین مرحله، مدل آموزشدیده دادهها را تحلیل و خروجی تولید میکند. این خروجی میتواند شامل تحلیل نحوی و معنایی، ترجمه متن، تولید پاسخ در یک چتبات یا حتی تولید یک متن جدید باشد.
برای پردازش و تحلیل زبان انسانی، الگوریتمهای مختلفی توسعه داده شدهاند که هر کدام رویکرد خاصی دارند. این الگوریتمها را میتوان به سه دسته اصلی تقسیم کرد:
این دسته از الگوریتمها مبتنی بر قواعد زبانی و دستنوشتههای انسانی هستند. در آنها قواعد دستوری و لغوی به صورت صریح تعریف میشوند. برای مثال، یک سیستم Rule-based میتواند جملهها را با توجه به ساختار نحوی آنها تحلیل کند. مزیت این روش شفافیت و قابلیت توضیحپذیری بالاست، اما مشکل آن در پوشش زبانهای متنوع و استثناهای فراوان است.
با رشد دادههای متنی و محاسبات آماری در دهه ۹۰، این رویکرد محبوب شد. الگوریتمهای آماری به جای تکیه صرف بر قواعد، از احتمال وقوع الگوهای زبانی استفاده میکنند. مثلاً برای ترجمه ماشینی، این الگوریتمها بررسی میکنند که چه احتمال دارد یک کلمه در زبان مقصد معادل یک کلمه در زبان مبدأ باشد.
این رویکرد تلاش میکند نقاط ضعف دو روش قبلی را پوشش دهد. در الگوریتمهای ترکیبی از قواعد زبانی همراه با مدلهای آماری یا یادگیری ماشین استفاده میشود. بسیاری از سیستمهای مدرن NLP مانند موتورهای جستجو و چتباتها از این رویکرد بهره میبرند.
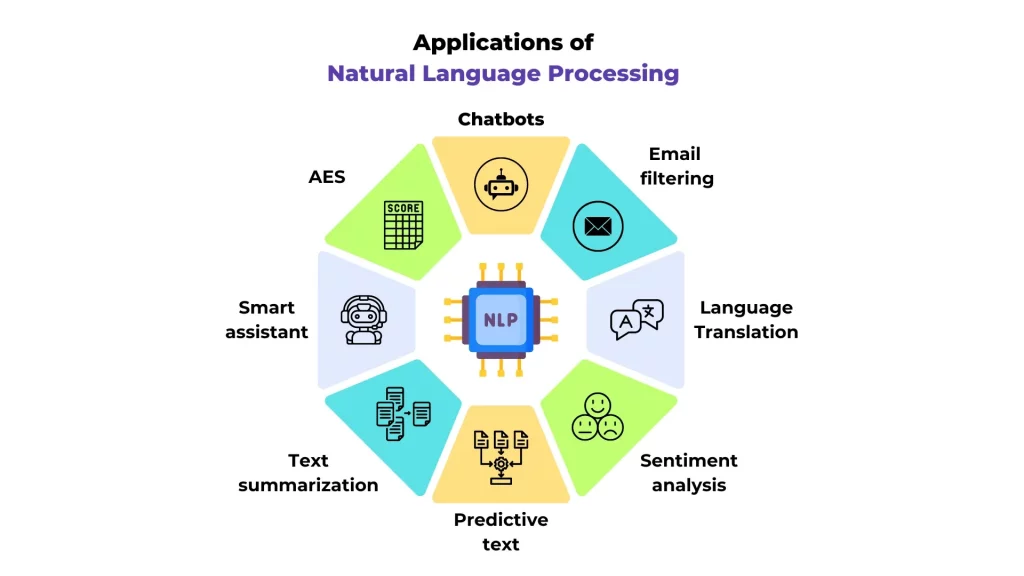
پردازش زبان طبیعی در حوزههای مختلف وظایف گوناگونی را پوشش میدهد. از جمله: تحلیل احساسات، طبقهبندی متن، شناسایی موجودیتهای نامدار، خلاصهسازی متن، ترجمه ماشینی، پاسخگویی به سؤالات، تصحیح خطاهای گرامری و مدلسازی موضوعات.
یکی از مهمترین وظایف NLP شناسایی احساسات مثبت، منفی یا خنثی در متن است. برای مثال، سیستمها میتوانند بازخورد کاربران در شبکههای اجتماعی یا نظرات مشتریان درباره یک محصول را تحلیل کرده و دیدگاه کلی آنها را مشخص کنند.
در این وظیفه، متنها براساس موضوع یا ویژگی خاصی دستهبندی میشوند. برای نمونه، ایمیلها به دستههای «اسپم» و «غیر اسپم» تقسیم میشوند یا مقالات خبری در دستههای ورزشی، سیاسی و اقتصادی قرار میگیرند.
در این بخش، سیستم نام اشخاص، مکانها، سازمانها، تاریخها و سایر موجودیتهای مهم در متن را تشخیص میدهد. مثلاً در جمله «ایلان ماسک مدیرعامل اسپیسایکس است»، موجودیتهای «ایلان ماسک» و «اسپیسایکس» استخراج میشوند.
NLP میتواند متون طولانی را به خلاصهای کوتاه و معنادار تبدیل کند. این قابلیت در تحلیل اسناد طولانی، مقالات علمی و اخبار بسیار کاربردی است.
یکی از شناختهشدهترین کاربردهای NLP، ترجمه خودکار بین زبانهاست. سرویسهایی مانند Google Translate نمونهای از این وظیفه هستند که از الگوریتمهای پیشرفته برای ترجمه روان استفاده میکنند.
در این وظیفه، سیستم با دریافت یک پرسش، پاسخ دقیق و مرتبطی ارائه میدهد. چتباتها و موتورهای جستجو از این قابلیت استفاده میکنند.
NLP میتواند خطاهای دستوری و نوشتاری را در متن تشخیص داده و نسخه اصلاحشده ارائه دهد. ابزارهایی مانند Grammarly از همین قابلیت بهره میبرند.
در این وظیفه، سیستم موضوعات اصلی موجود در مجموعهای از متون را شناسایی میکند. این کار برای دستهبندی خودکار مقالات یا تحلیل محتوای شبکههای اجتماعی بسیار مفید است.
با ورود شبکه عصبی و یادگیری عمیق، پردازش زبان طبیعی جهشی بزرگ را تجربه کرد. مدلهای زبانی پیشرفته توانستند به جای تکیه بر قواعد یا روشهای آماری ساده، معنای عمیقتر و بافت زبانی را درک کنند.
مدلهای سنتی NLP معمولاً محدود به تحلیل سطحی متن بودند؛ مثلاً شمارش کلمات یا بررسی ساختار نحوی. اما مدلهای مدرن بر پایه ترنسفورمرها (Transformers) طراحی شدهاند که قابلیت یادگیری روابط پیچیده بین کلمات را در کل متن دارند.
مدلی است که توسط گوگل معرفی شد و امکان درک متن را به صورت دوطرفه فراهم میکند. به این معنی که یک کلمه را هم براساس کلمات قبل و هم بعد از آن تحلیل میکند. BERT در بسیاری از وظایف NLP مانند جستجو، طبقهبندی و استخراج موجودیتها دقت بالایی ارائه داده است.
سری مدلهای GPT توسط OpenAI معرفی شدند و تمرکز اصلی آنها روی تولید متن روان و طبیعی است. این مدلها ابتدا با حجم عظیمی از دادهها آموزش داده میشوند و سپس میتوانند متن تولید کنند، به پرسشها پاسخ دهند یا حتی داستاننویسی کنند.
برخلاف مدلهای قدیمی که اغلب روی دادههای محدود و قواعد مشخص عمل میکردند، مدلهای جدید توانایی تعمیمپذیری بالاتری دارند. آنها میتوانند از میلیاردها پارامتر استفاده کنند و متونی بسیار نزدیک به زبان طبیعی انسان تولید نمایند.
به همین دلیل، امروزه ابزارهایی مانند ChatGPT یا موتور جستجوی گوگل بیش از هر زمان دیگری توانستهاند تجربهای هوشمند و طبیعی را در تعامل با کاربر فراهم کنند.
پردازش زبان طبیعی تنها محدود به یک حوزه خاص نیست، بلکه در بخشهای مختلف زندگی روزمره و صنایع گوناگون نقش کلیدی ایفا میکند.
زبان نوشتاری یکی از اولین حوزههایی است که NLP در آن به کار گرفته شد.
زبان گفتاری نیز با استفاده از NLP و تکنیکهای پردازش صوت پیشرفت زیادی داشته است.
| حوزه | نمونه کاربردها | توضیحات |
| متن | ترجمه ماشینی | ترجمه متن میان زبانهای مختلف (مثل Google Translate) |
| چتباتها و دستیارهای هوشمند | پاسخگویی خودکار به کاربران در وبسایتها و اپلیکیشنها | |
| خلاصهسازی متن | استخراج مهمترین بخشهای متنهای طولانی | |
| تحلیل احساسات | شناسایی مثبت، منفی یا خنثی بودن یک متن | |
| طبقهبندی متن و استخراج کلمات کلیدی | دستهبندی اخبار، ایمیلها یا مقالات به موضوعات مختلف | |
| تصحیح خطای گرامری | شناسایی و اصلاح اشتباهات نوشتاری (مانند Grammarly) | |
| گفتار و تعامل | سیستمهای تشخیص صدا | تشخیص و تبدیل گفتار به متن (Speech-to-Text) |
| دستیارهای صوتی | Siri، Alexa و Google Assistant برای پاسخگویی صوتی | |
| تعامل انسان-رایانه (HCI) | برقراری ارتباط طبیعی بین انسان و ماشین | |
| صنایع مختلف | پزشکی | تحلیل متون پزشکی یا گزارشهای بیماران برای تشخیص بیماری |
| مالی | تحلیل دادههای متنی گزارشها و اخبار اقتصادی در معاملات الگوریتمی | |
| بازاریابی و خدمات مشتری | اتوماسیون پشتیبانی مشتری و تحلیل بازخوردها | |
| موتورهای جستجو و SEO | بهبود نمایش نتایج جستجو و تحلیل کوئریهای کاربران |
پردازش زبان طبیعی علاوهبر جنبههای نظری، ابزارها و فریمورکهای متنوعی هم دارد که کار توسعهدهندگان و پژوهشگران را آسانتر میکند. این ابزارها امکان پیادهسازی سریع الگوریتمها، آزمایش مدلهای مختلف و حتی استفاده از مدلهای آماده را فراهم میکنند.
بیشتر پروژههای پردازش زبان طبیعی با زبانهای پایتون و جاوا توسعه داده میشوند.

برای نمونه، کد زیر نشان میدهد که چطور میتوان با استفاده از NLTK یک متن ساده را به کلمات شکسته (Tokenize) کرد:
import nltk
from nltk.tokenize import word_tokenize
from nltk.corpus import stopwords
# دانلود دادههای موردنیاز در اولین اجرا
nltk.download('punkt')
text = "Natural Language Processing aka NLP has Many Libraries in Python."
tokens = word_tokenize(text)
print(tokens)
stop_words = set(stopwords.words('english')) # برای فارسی میتوان لیست سفارشی ساخت
filtered_words = [w for w in word_tokens if w.lower() not in stop_words]
print("بدون کلمات توقف:", filtered_words)
خروجی این کد لیستی از کلمات متن و حذف کلمات پرتکرار یا اضافی است که در مراحل بعدی میتواند برای تحلیلهای مختلف مورد استفاده قرار گیرد.
پردازش زبان طبیعی بهعنوان یکی از شاخههای مهم هوش مصنوعی، توانسته تحول بزرگی در تعامل میان انسان و ماشین ایجاد کند. بااینحال، همانند بسیاری از فناوریها، هم مزایا دارد و هم محدودیتها.
یکی از مهمترین مزایای NLP، سرعت و دقت بالا در پردازش حجم عظیمی از دادههای متنی است. درحالیکه انسان نمیتواند در زمان کوتاه میلیونها کلمه را بخواند و تحلیل کند، سیستمهای NLP این کار را در چند ثانیه انجام میدهند.
از دیگر مزایا میتوان به اتوماسیون فرآیندها اشاره کرد؛ مثلاً پاسخگویی خودکار به مشتریان، تحلیل احساسات در شبکههای اجتماعی، یا دستهبندی مقالات بدون نیاز به نیروی انسانی. همچنین مقیاسپذیری بالا باعث میشود سازمانها بتوانند دادههای متنی گستردهای را بهطور همزمان پردازش کنند.
در کنار مزایا، محدودیتهایی نیز وجود دارد. یکی از اصلیترین چالشها چندمعنایی بودن کلمات است؛ بهعنوان مثال، کلمه «شیر» در فارسی میتواند به حیوان، نوشیدنی یا وسیله آب اشاره داشته باشد. همچنین زبان طبیعی بسیار پیچیده است و ساختارهای گرامری یا اصطلاحات محاورهای اغلب برای ماشینها دشوار هستند.
دیگر محدودیت، نیاز به دادههای حجیم و باکیفیت است. برای آموزش مدلهای NLP به میلیونها نمونه متنی نیاز داریم و اگر این دادهها ناقص یا نامتوازن باشند، نتایج دقیق نخواهد بود.
با وجود پیشرفتهای چشمگیر، پردازش زبان طبیعی هنوز با موانع و دشواریهایی روبهرو است که حل آنها نیازمند تحقیقات گسترده و دادههای بهتر است.
یکی از بزرگترین چالشها، ابهام زبانی (Ambiguity) است. بسیاری از کلمات و جملات در زبان طبیعی میتوانند معانی مختلفی داشته باشند. برای نمونه، جملهی «من کتاب را دیدم» میتواند به دیدن فیزیکی کتاب یا مطالعه آن اشاره داشته باشد. تشخیص معنای دقیق این موارد برای ماشین کار سادهای نیست.
چالش دیگر مربوط به تنوع زبانها و گویشها است. هر زبان دارای قواعد دستوری، لغات و حتی اصطلاحات خاص خود است. علاوهبرآن، زبانهای محاورهای و گویشهای محلی باعث میشوند که آموزش مدلهای جامع بسیار دشوار شود.
همچنین، درک مفاهیم پیچیده و زمینهمحور هنوز محدودیت دارد. برای مثال، سیستمها ممکن است در فهم کنایه، طنز یا مفاهیم استعاری دچار خطا شوند. حتی مدلهای پیشرفته نیز برای درک عمیق متون فلسفی، ادبی یا محتوای فرهنگی خاص نیاز به دادههای بیشتری دارند.
در کنار این موارد، مسائل اخلاقی و امنیتی نیز مطرح هستند. مدلهای NLP ممکن است به دلیل دادههای آموزشی نادرست دچار سوگیری شوند یا اطلاعات حساس کاربران را به شکل ناخواسته پردازش کنند.
پردازش زبان طبیعی درحالحاضر یکی از پرشتابترین حوزههای فناوری است و انتظار میرود در سالهای آینده تحولات چشمگیری در آن رخ دهد.
یکی از روندهای مهم، رشد سرمایهگذاریها در NLP است. شرکتهای بزرگ فناوری و حتی استارتاپها منابع زیادی را صرف توسعه مدلهای زبانی و ابزارهای هوشمند کردهاند تا بتوانند تجربه کاربری بهتری ایجاد کنند.
همچنین، استفاده گستردهتر از تولید زبان طبیعی (NLG) در تولید محتوا پیشبینی میشود. سیستمها قادر خواهند بود متون خبری، گزارشهای مالی یا حتی محتوای خلاقانه را بهصورت خودکار و با کیفیتی نزدیک به نویسندگان انسانی تولید کنند.
در حوزه تعامل انسان و ماشین، دستیارهای محاورهای هوشمندتر خواهند شد. به جای پاسخهای ساده، این دستیارها میتوانند گفتوگوهای چندمرحلهای و طبیعیتر با کاربران داشته باشند.
یکی دیگر از نقاط عطف آینده، نقش مدل های زبانی بزرگ (LLMs) مانند ChatGPT خواهد بود. این مدلها نه تنها درک عمیقتری از زبان ارائه میدهند، بلکه میتوانند به ابزارهایی چندمنظوره برای آموزش، تحقیق، تولید محتوا و حتی برنامهنویسی تبدیل شوند.
با توجه به رشد سریع هوش مصنوعی و بهویژه پردازش زبان طبیعی، بازار کار این حوزه نیز بهطور چشمگیری گسترش یافته است. شرکتهای فناوری، استارتاپها و حتی سازمانهای سنتی به دنبال متخصصانی هستند که بتوانند از دادههای متنی و گفتاری ارزش استخراج کنند.
این نقش شامل بررسی و تحلیل حجم زیادی از دادههای متنی برای استخراج الگوها، روندها و بینشهای کاربردی است. تحلیلگران دادههای متنی معمولاً با ابزارهای آماری و یادگیری ماشین کار میکنند.
یکی از پرتقاضاترین موقعیتها، توسعه چتباتها و دستیارهای مجازی است. این افراد مسئول طراحی سیستمهایی هستند که بتوانند بهطور طبیعی با کاربران تعامل داشته باشند.
پژوهشگران در حوزه NLP روی توسعه الگوریتمهای جدید، بهبود مدلهای زبانی و رفع چالشهای موجود (مثل درک کنایه یا چندمعنایی) تمرکز میکنند. این نقش بیشتر در شرکتهای پیشرفته فناوری و مراکز تحقیقاتی دیده میشود.
در سطح جهانی، متخصصان NLP فرصتهای شغلی گستردهای در شرکتهای فناوری بزرگ مانند گوگل، مایکروسافت، آمازون و OpenAI دارند. در ایران نیز با رشد استارتاپهای حوزه فناوری و نیاز به سیستمهای هوشمند، تقاضا برای متخصصان NLP رو به افزایش است. حوزههایی مانند فینتک، سلامت دیجیتال، آموزش آنلاین و بازاریابی دیجیتال از مهمترین بازارهای داخلی محسوب میشوند.
پردازش زبان طبیعی (NLP) یکی از مهمترین شاخههای هوش مصنوعی است که امکان درک و تولید زبان انسانی توسط ماشینها را فراهم میکند. این حوزه ترکیبی از زبانشناسی محاسباتی، یادگیری ماشین و یادگیری عمیق است و در کاربردهای گستردهای مانند ترجمه ماشینی، تحلیل احساسات، چتباتها، سیستمهای تشخیص صدا و موتورهای جستجو نقش کلیدی دارد.
با وجود پیشرفتهای چشمگیر، NLP همچنان با چالشهایی مانند ابهام زبانی، چندمعنایی بودن کلمات و نیاز به دادههای حجیم روبهرو است. بااینحال، ظهور مدلهای زبانی پیشرفته مانند BERT و GPT نشان میدهد که آینده این حوزه به سمت درک عمیقتر زبان و تعامل طبیعیتر انسان و ماشین حرکت میکند.











